This is the multi-page printable view of this section. Click here to print.
Blog
Continuous Delivery
Continuous Delivery (CD) is deeply rooted in the first principle of the Agile Manifesto posted in 20011:
Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
According to Martin Fowler2, a project is truly embracing Continuous Delivery when:
- The software can be deployed at any stage of its lifecycle.
- The team values keeping the software deployment-ready over adding new features.
- Any software version can be deployed to any environment on-demand.
In many ways, Continuous Delivery is the next step from Continuous Integration, seamlessly automating processes all the way to the software’s end user.
Much like in Continuous Integration, the pipeline stands as the cornerstone of Continuous Delivery. However, it’s not just about integrating code, testing it, and generating a deliverable artifact. With CD, this artifact progresses through a series of test phases in environments that increasingly resemble production settings. After passing through the Continuous Integration pipeline, what emerges is a potentially deployable artifact. CD then takes this artifact and puts it through the necessary tests, ensuring it’s primed for a live deployment.
The delivery process
The following figure illustrates the fundamental steps of a Continuous Delivery (CD) process. It’s vital to note that an effective CD process presupposes a well-oiled Continuous Integration (CI) system as its foundation.
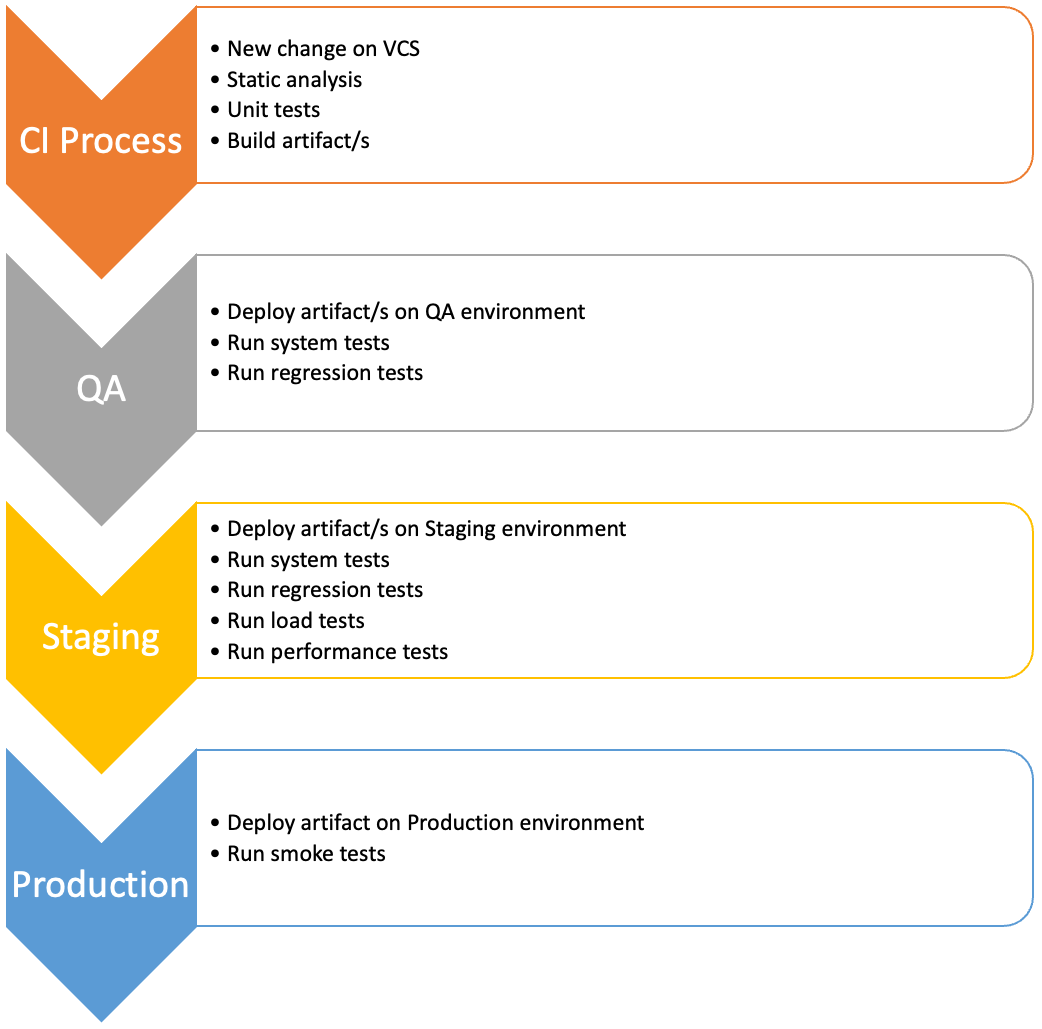
Figure 1: CD process flowchart
The CD process adds two distinct phases to the CI system: deployment stages and system validation and verification testing. A critical premise is that the deployment process is paramount to product delivery. Thus, automating and frequently testing it is essential. Ideally, testing should also be automated to facilitate execution, especially if you aim for Continuous Deployment. However, it’s not imperative to automate all tests, especially at the beginning of the CD process implementation.
Upon creating a potentially deliverable artifact in the CI pipeline, the initial step is to deploy it in a testing or QA environment. The primary goal of this environment is to offer a space where software tests, both automatic and manual, can be run. The only possible variations between the QA and actual production environment (the one used by customers) may pertain to its capacity or resource size. This scaled-down capacity, whether in processing, memory, storage, or database size, is typically a cost-saving measure.
If system and acceptance tests are successful in the QA environment, the next phase is to deploy the artifact in a staging environment. This environment should be an exact replica of the production setting. Its purpose is to facilitate performance and load testing on the system, effectively putting it under stress to validate its functionality under high loads and assess its processing and response times.
When the previous tests are satisfactory, the artifact is ready to be deployed in a production environment. This space is also referred to as the live environment, where users interact with the system.
As evident, the product deployment method is exercised at least twice before the final production deployment, considerably reducing risks associated with potential errors as the final delivery approaches.
Core principles and practices
One of CD’s primary objectives is to boost delivery frequency. This naturally means that each release should minimize its size. A smaller delivery not only implies fewer potential errors but also facilitates their identification and resolution2. To achieve this, the code must always be in a deploy-ready state.
Rapid automated testing is crucial for today’s software development3. In the context of CD, automated tests are of utmost importance as they must ensure comprehensive system quality without hampering the delivery cycle’s speed4. Lengthy test runs force the team to await results, leading to wasted time3. If these tests aren’t parallelized and optimized, developers may start sidelining them5. To ensure test optimization, it’s recommended to fail tests that exceed a reasonable limit6.
The software should always be potentially deliverable. It’s essential for the software’s build status to remain ‘green’ consistently. This means if a new repository commit breaks the build, this error must be rectified before any new commit is made. Adhering to this practice simplifies error tracing, while deviating may condition developers to overlook a broken or ‘red’ build6. Broken builds signify product flaws and render it undeliverable.
In using CD, the aim is to ensure each commit results in a production-ready artifact. If this artifact is rebuilt at every process stage, there’s no guarantee of their identical nature, and validation and verification test results from one artifact cannot be applied to others. This could lead to deploying untested artifacts6. Hence, artifacts should be produced only once and undergo all tests on that single artifact before deploying that very software piece to production.
Software should always be deployed identically across all environments. Otherwise, there’s no assurance of the deployment process’s efficacy. If environment differences exist, they should be managed using configuration files, but the deployment process should remain consistent6.
Deployment should be achievable with a mere button press. The ability to deploy the latest product version anytime with a single button press is a robust indicator of CD implementation2. This not only requires the aforementioned steps but also mandates version-controlled software deployment scripts that are regularly checked and validated6.
As mentioned earlier, CD’s main objective is to ascertain the product’s readiness post each commit2. For this, aside from ensuring a swift compilation and testing process, process outcomes should be visible and shared with the team. Display screens showcasing the current status, build times, test coverage, and more, offer a way to maintain constant visibility6. Presenting these results not only supports CD but, as some authors suggest, also bolsters team motivation4.
Benefits of Continuous Delivery
With the rise of Continuous Delivery (CD) practices, businesses are realizing numerous advantages:
Swift value delivery: the adoption of CD practices facilitates a faster rollout of features and error rectifications to end users7. This speed is attributed to the code becoming potentially deployable to users as it traverses through the Continuous Integration (CI) pipeline4.
Diminished delivery failures: frequent releases lead to fewer delivery risks since each release embodies fewer changes. This, in turn, means there’s a reduced margin for errors2. Even if an error emerges, its origin is easier to trace and correct. Plus, reverting to a previous version in the face of complications becomes straightforward8. A delightful by-product of this streamlined process is the diminished stress levels amongst stakeholders7 5. Furthermore, the consistency and quality in the delivery process cement trust between the development team and clients7.
Productivity amplification: Chen’s study reveals that, in the absence of CD practices, teams spent nearly \(20%\) of their time setting up and maintaining environments7. The introduction of CD automates this ordeal, which translates to heightened productivity by phasing out manual, non-value-add tasks6.
Prompt feedback: a consensus among experts highlights the value of early feedback during the development phase2 7 4. Regular releases not only fetch this feedback promptly but also ensure that the developed product aligns seamlessly with customer requirements2. The agility to swiftly address customer needs, fix reported bugs, and introduce demanded features can significantly elevate customer satisfaction4.
Enhanced software quality: the rigorous automation of software tests (unit, integration, and system), essential for implementing CD, combined with more frequent software deliveries encapsulating fewer changes, culminates in a notable boost in software quality4.
Transparency in progress: thanks to frequent releases, clients find it easier to stay abreast of the latest product updates, embracing novel features and bug fixes with open arms.
Challenges in adopting Continuous Delivery
The journey to incorporate Continuous Delivery (CD) isn’t without its hurdles. Here’s a look at some of the key challenges faced by businesses:
Product complexity: certain products consist of myriad interconnected modules or possess dependencies with other projects. This can create bottlenecks when automating CD pipelines4. Such complexities might frustrate teams, pushing them to retain manual processes or longer integration procedures.
Test suite creation: crafting a comprehensive test suite to ensure product quality is labour-intensive. All team members must allocate significant time to pen tests, which might require extra training. Besides, tests can be time-consuming, so the trick lies in devising effective yet swift tests4.
Legacy code: systems that have been in development for an extended period and weren’t designed with automated testing in mind can pose a significant challenge. Transitioning such systems to CD is not only a technical endeavour but also a social and cultural shift4.
Environmental discrepancies: all environments in the CI pipeline should mirror the production setting (‘production-like’)6. If not, unforeseen errors can arise, demanding valuable time on non-value-add tasks4. Ensuring multiple deployment stages in similar environments means that the deployment process is tested repetitively.
Client restrictions: not every client might desire or require a shortened product delivery cycle4. Such client limitations aren’t direct obstacles to CD implementation but play a pivotal role when aiming for Continuous Deployment. This could potentially sideline some CD benefits, like swift client feedback or minimal change deliveries. Moreover, the domain itself can act as a bottleneck. Software related to heavily-regulated sectors like healthcare and defence may find CD implementation challenging, if not nearly impossible4.
Transparency and reporting: a successful CD adoption hinges on collaboration and transparency, introducing challenges tied to providing effective status reports to stakeholders9. This encompasses technical hurdles around automated report generation and analytics challenges to pinpoint essential information.
Resistance to change: any transformative change, like adopting CD, faces the innate human trait of resistance. Convincing the team to adapt to new practices and modify their workflow is a task. On a higher level, management might also be hesitant to experiment with fresh processes.
Continuous Deployment
The notion of Continuous Deployment was popularized by Fitz10. The standout distinction between this method and Continuous Delivery (CD) is that, once the product is deemed ready for release, there’s no waiting for manual intervention to launch it into production11 6. If CD is properly executed, the step towards Continuous Deployment should demand no extra efforts from the development perspective8. In essence, the core difference lies in decision-making: with CD, releasing the product to production remains a business decision, whereas with Continuous Deployment, the launch is automated.
It’s worth noting that when we discuss CD, it inherently includes Continuous Delivery but may or may not encompass Continuous Deployment.
References
Beck, Kent, Mike Beedle, Arie van Bennekum, Alistair Cockburn, Ward Cunningham, Martin Fowler, James Grenning, Jim Highsmith, Andrew Hunt, Ron Jeffries, Jon Kern, Brian Marick, Robert C. Martin, Steve Mellor, Ken Schwaber, Jeff Sutherland, and Dave Thomas. Manifesto for Agile Software Development, 2001. ↩︎
Fowler, Martin. Continuous Delivery, 2013. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Udd, Raoul. Adopting Continuous Delivery: A Case Study, 2016. ↩︎ ↩︎
Leppanen, Marko, Simo Makinen, Max Pagels, Veli-Pekka Eloranta, Juha Itkonen, Mika V. Mantyla, and Tomi Mannisto. The highways and country roads to continuous deployment. IEEE Software, 32(2):64-72, 2015. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Neely, Steve, and Steve Stolt. Continuous delivery? Easy! Just change everything (well, maybe it is not that easy). Proceedings - AGILE 2013, pp.121-128, 2013. ↩︎ ↩︎
Humble, Jez, and David Farley. Continuous Delivery: Reliable Software Releases through Build, Test and Deployment Automation. Addison-Wesley, 2011. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Chen, Lianping. Continuous Delivery: Huge Benefits, but Challenges Too. IEEE Software, 32(2):50-54, 2015. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Humble, Jez. Continuous Delivery vs Continuous Deployment, 2010. ↩︎ ↩︎
Olsson, Helena Holmstrom, Hiva Alahyari, and Jan Bosch. Climbing the “Stairway to Heaven” – A Multiple-Case Study Exploring Barriers in the Transition from Agile Development towards Continuous Deployment of Software. 2012 38th Euromicro Conference on Software Engineering and Advanced Applications, pp.392-399, 2012. ↩︎
Fitz, Timothy. Continuous Deployment, 2009. ↩︎
Pulkkinen, Ville. Continuous Deployment of Software. Proceedings of Cloud-Based Software Engineering, pp.46-52, 2013. ↩︎
Continuous Integration
One of the most pivotal challenges in the realm of software development is effectively integrating changes 1. In a small-scale project steered by a single developer, this challenge might appear to be trivial. However, as the magnitude of the project escalates and more individuals join the development fold, the significance of seamless integration becomes paramount.
Historically, integration was often an afterthought, relegated to the tail end of the software development process 2. Postponing it to such a late stage not only amplifies the risk of complex, undetected errors but also heightens the tension as delivery dates loom.
However, the paradigm shifted around the turn of the millennium. Continuous Integration (CI) was formally introduced in 2000 by Kent Beck as an intrinsic part of the ‘Extreme Programming’ methodology 3. CI emphasizes the frequent and early-stage integration of code. By continuously amalgamating new code into the system, developers can gauge its impact promptly. This approach streamlines error detection, enabling developers to tackle issues as they emerge 2. The ability to tie an error to a specific code change reduces error complexity and promotes efficient troubleshooting. Today, CI has become an indispensable practice in software development projects 4.
Martin Fowler, a luminary in the field, eloquently defined CI as:
Continuous Integration is a software development practice where team members integrate their work frequently, typically multiple times a day. Each integration is verified by an automated build system that runs test suites to swiftly detect any integration anomalies. Teams adopting this methodology often witness a significant reduction in integration hiccups, empowering them to produce cohesive software at an accelerated pace2.
Building upon Fowler’s definition, Duvall 5 underscored several vital facets:
- Developers must maintain a conducive local environment for code construction and testing, ensuring their updates do not disrupt the established integration.
- Team members should commit their code to the Version Control System (VCS) daily.
- The integration process must be undertaken on a distinct machine, aptly termed the CI server.
- Only builds that pass all tests can be deemed deliverable.
- Error resolution is of paramount importance.
- A central repository displaying build and test results—often a website—is essential. Most CI tools readily offer such platforms.
Furthermore, Patrick Cauldwell 6 advocates for frequent and early integration. The rationale? The more regular the integration, the less overhead for the team down the line. He distilled the primary goals of CI into:
- Ensuring a consistently available, tested version of the product with the latest modifications.
- Keeping the team abreast of any integration issues as early as possible.
The impetus behind CI is to maintain an error-free, tested product throughout the development life cycle. This avoids the pitfalls of a last-minute integration phase, which is often fraught with errors and consumes both time and resources. More crucially, if project components aren’t integrated during their development, there’s no guarantee they’ll gel cohesively in the final product 7.
Technical implementation of CI revolves around two core components: process automation and a system to showcase results, thereby fuelling the developmental feedback loop 7.
In summing up the tenets of CI, Martin Fowler 1 emphasizes:
- Retaining code in a singular repository.
- Streamlining software construction through automation.
- Implementing automated testing processes.
- Ensuring new code additions undergo integration and construction on the CI system’s machine.
- Keeping the build process agile and swift.
- Providing easy access to the product’s latest executable version.
- Ensuring product status transparency for all stakeholders.
Elements of a CI system
A basic Continuous Integration (CI) pipeline initiates when a new code change is pushed to the repository. The CI server, linked to the repository, gets notified of every new change, subsequently downloading the latest version to initiate the integration process, which will be elaborated on in the subsequent section. Once completed, it communicates the system’s status to the team members.
In computer science, a “pipeline” refers to a sequence of processes or tasks linked such that the output of one becomes the input for the next.
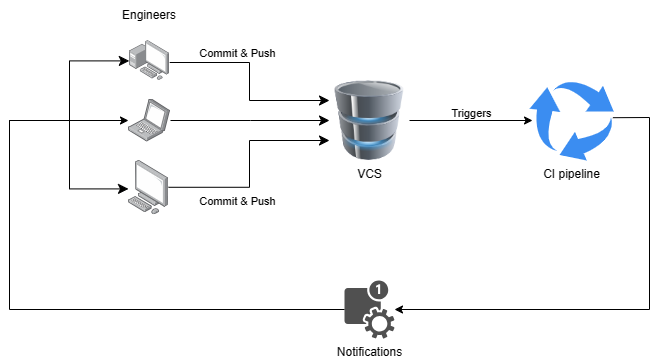
Figure 1: Basic elements of CI (Duvall5)
The system’s primary component consists of the developers. After making code modifications, they run tests locally and compile the code to ensure that they haven’t introduced new errors.
An essential part of every CI system is the Version Control System (VCS). It oversees the changes made to the code and other significant elements. This system establishes a unified access point for all source code, enabling the CI system to fetch the most recent version for integration. Most software development projects utilize a VCS even if they don’t implement CI processes.
The CI Server is responsible for initiating a new build (comprising both compilation and tests) every time a change is added to the repository. They offer configurations to simplify the creation of integration pipelines. Additionally, most come with a web interface to display the build status and previous results. Currently, numerous powerful options are available, both free and paid. It’s worth noting that the CI server should operate on a dedicated machine and not on team members’ computers.
The CI server must automatically conduct software tests, source code analysis, and compile to produce the deliverable product. Therefore, build and test execution scripts are vital. These scripts outline the necessary steps to be executed. Popular tools for this purpose include Make, Ant, Maven, Gradle, among others.
Every CI system should have a notification mechanism to relay results to the team. This mechanism ensures that in the event of an error, the team becomes aware as soon as possible, enabling them to address the issue. While most CI tools offer a web interface to view results, they also support other notification methods like emails, messaging applications, etc.
The integration process
The figure below broadly illustrates the stages of the integration process taking place within the Continuous Integration (CI) system.
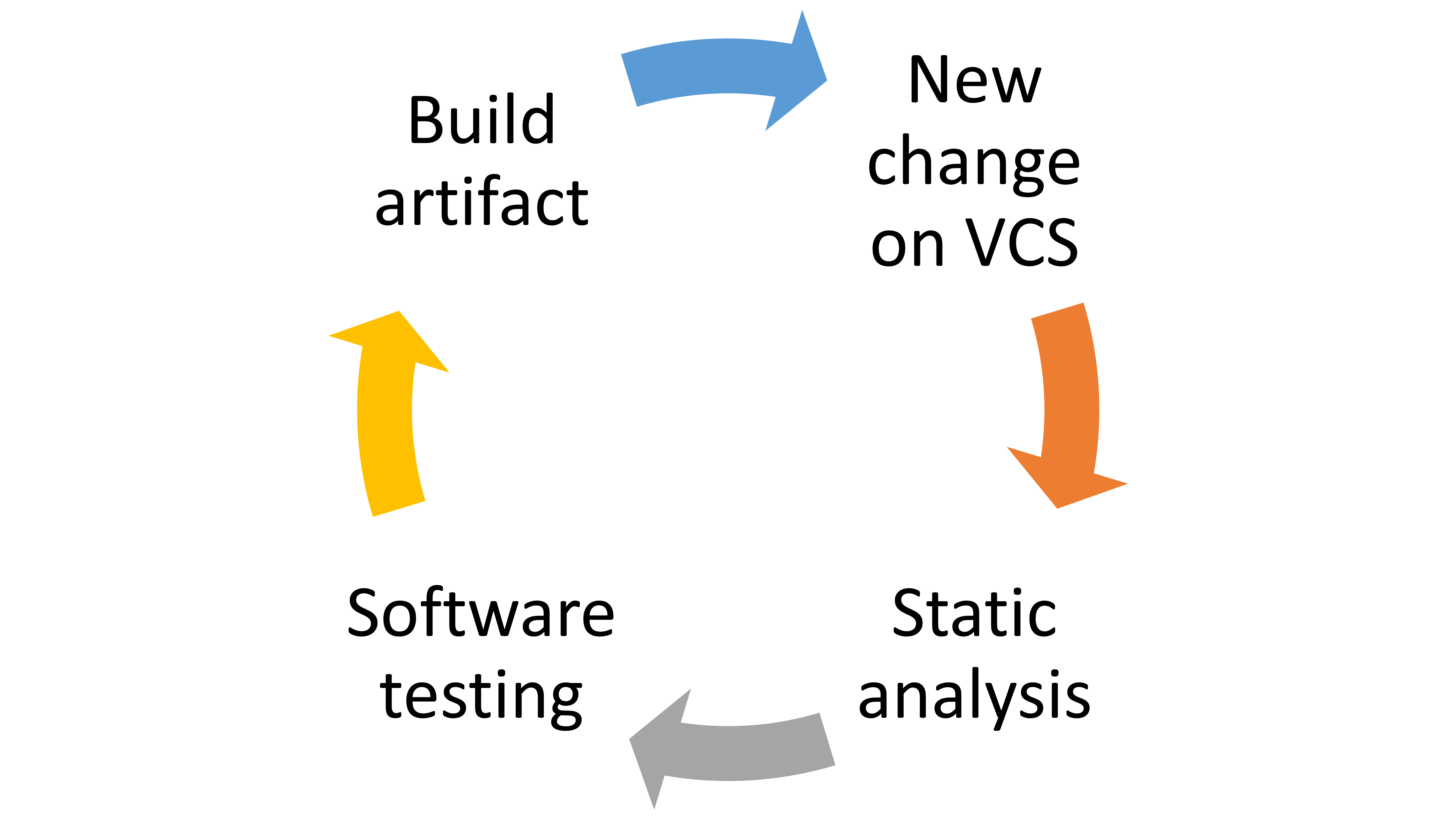
Figure 2: CI process flowchart
Initially, the system must retrieve the latest source code version each time a new change is pushed to the Version Control System (VCS). Two mechanisms facilitate this. The first involves setting up the CI server to periodically check the VCS for updates. The alternative is to establish a commit hook within the VCS, ensuring that the CI server receives notifications whenever changes are made.
After obtaining the code, the CI server can be configured to scrutinize the source code for potential undetected errors, be they syntactic, logical, or patterns that might lead to faults. Various tools aid this process. For instance, Java boasts utilities like FindBugs, CheckStyle, and PMD, while Python has Pylint. JavaScript can be analysed with tools like JSLint or JSHint. An example of a code analysis criterion could be ensuring every developed method has a cyclomatic complexity8 under 10. By employing automated source code inspection, one can assess code correctness, spot duplicate portions, and expedite the time between error detection and rectification. While automated inspection might not catch every error, the results can approximate those of peer reviews, thereby lightening the team’s review load.
The subsequent step revolves around automated test execution on the product. This automation is paramount to successfully implementing a CI system. Thus, developers can confidently make alterations, knowing a robust testing framework safeguards against compromising existing functionalities. Some popular tools in this domain include Junit, JBehave, and Selenium, which not only facilitate test drafting but also generate comprehensive reports, often as visualizations or web pages. Several software testing levels exist, such as unit tests, integration tests, and system tests. In the CI pipeline context, the focus rests on automating unit and integration tests, with system tests’ automation being recommended but not mandatory.
Once the tests pass, the CI pipeline advances to compiling the source code. During this phase, the source code morphs into one or multiple files or packages, ready for distribution and user execution. This process’s specifics hinge on the employed programming language. For instance, languages like Java necessitate code compilation, resulting in an executable. Conversely, languages like Python might involve stricter code structure checks without generating any binary files.
Throughout this integration journey, the team should steadfastly adhere to three fundamental rules:
- Locally run tests and compile software before integrating it into the VCS to minimize error introduction chances (avoiding “breaking the build”).
- Avoid pushing new code to the VCS if the CI server flags errors (indicative of a “broken build”).
- Should the CI server report faults, code modifications should exclusively aim at rectifying them.
Core principles and practices
Martin Fowler2 identifies a set of foundational elements intrinsic to every Continuous Integration (CI) system. While some of these have been touched upon earlier in this chapter, we will succinctly encapsulate them here for clarity:
- Centralized Code Repository: Retain all code within a singular, unified repository.
- Streamlined Compilation and Build Process: Entirely automate the compilation and construction workflows, negating manual intervention.
- Full-Spectrum Automated Testing: Ensure all software tests are automated, driving efficiency and precision.
- Daily Commitment: Encourage the team to consistently merge their changes to the repository on a daily basis.
- Stringent Integration Checks: Each alteration made to the Version Control System (VCS) undergoes rigorous integration processes within the CI system.
- Prompt Error Rectification: Should the CI system flag any issues (indicative of a “broken build”), immediate action is imperative. Either rectify the flaw or reverse the change to ensure the repository’s latest version remains operational.
- Swift CI Procedures: Aim to complete the CI process rapidly—ideally within 15 minutes or less. This approach ensures timely integration and facilitates the expedited delivery of results.
- Universal Access to Latest Executables: Always provide the team with access to the most recent executable or deliverable package, promoting transparency.
- Real-time Product Status Visibility: Grant every team member the ability to monitor the product’s status at any given moment, fostering informed decision-making.
Benefits
The overarching consensus within the software community is that the implementation of a Continuous Integration (CI) process yields an array of substantial advantages. Duvall5 outlines these core benefits in his publication.
Risk Mitigation: Adopting frequent integration minimizes project risks. It facilitates early detection of issues and offers a continuous snapshot of the product’s health. By identifying these issues early in the development cycle, there’s a consequent reduction in both the cost of fixes and the risk of releasing a subpar product. Furthermore, automated inspections provide real-time insights into the product’s size, code complexity, and other metrics. This automation diminishes the chance of human-induced errors.
Minimization of Manual Repetitive Tasks: Automation curtails the need for recurring manual tasks such as compilation, inspection, test execution, and report generation. This efficiency not only leads to significant time and cost savings but also allows teams to focus on activities that directly enhance product value. It liberates team members to dedicate more time to addressing new requirements or rectifying existing product issues.
On-Demand Availability of a Functional Product: A hallmark of CI is its ability to deliver a functional software product at any given moment. This is invaluable for stakeholders, offering them a rapid glance into product development progress. By leveraging CI, errors can be swiftly detected and remedied soon after a new change is introduced. This is far more efficient than uncovering them close to the release date when they are more expensive and challenging to amend. Such issues, if left unchecked, can lead to delivery delays, unsatisfied clients, escalated costs, and more. This ties back to the concept of the “Broken Window Theory”9, which, in essence, postulates that a product marred by numerous issues or perceived disorder can demotivate teams from addressing them.
Enhanced Project Transparency: Implementing CI augments visibility into the project, rendering the development process more transparent. It aids project management with up-to-the-minute information, making it straightforward to gauge product quality, error trends, and more.
Elevated Product Confidence: The CI environment bolsters confidence in the product. Team members gain immediate insights into the ramifications of their changes, enabling them to promptly rectify any emergent issues.
Challenges
While Duvall5 has extolled the virtues of Continuous Integration (CI) in his works, he also highlights potential challenges that might deter development teams from embracing it fully or realizing its benefits.
Bias: A widespread misconception is that CI system implementation is exorbitant and would escalate development costs due to its prolonged setup and maintenance. Contrarily, most software development projects already involve phases like inspection, testing, compilation, and integration, even if they don’t explicitly use a CI system. A common refrain is that there’s insufficient time or funds for CI system implementation, but the reality is that far more resources are spent performing redundant manual tasks throughout the development cycle. Furthermore, an automated CI system is infinitely more manageable and consistent compared to disparate manual processes.
Disruption Fears: Projects in advanced development stages often fret that integrating a CI system would overhaul their established workflows, spawning significant delays. It’s pivotal to recognize that CI system implementation can be incremental. Teams can address one integration stage at a time, gradually ramping up the integration frequency as confidence builds.
Overwhelming Failed Integrations: When CI practices aren’t diligently applied, there’s a risk of encountering an excessive number of failed integrations or “broken builds.” This could stem from developers bypassing local tests before uploading their changes to the Version Control System (VCS). A surge in failed integrations can erode trust in the CI system, reminiscent of the “Broken Window Theory”9.
Perceived Additional Costs: There’s an apprehension among organizations about incurring extra expenses either for procuring CI product licenses or securing hardware to support these systems. However, this expenditure pales in comparison to the latent costs of late-stage integrations, where issues are discovered near the release date, far removed from their inception. On a brighter note, the current landscape is rife with a myriad of free and open-source alternatives, obviating any additional costs.
References
Continuous integration. ThoughtWorks, 2018. ↩︎ ↩︎
Fowler, Martin. Continuous Integration. 2006. ↩︎ ↩︎ ↩︎ ↩︎
Beck, Kent. Embrace Change with Extreme Programming. IEEE Computer Magazine, (c), 70-77. 1999. ↩︎
Rodriguez Pilar, Markkula, Jouni, Oivo, Markku, & Turula, Kimmo. Survey on agile and lean usage in Finnish software industry. In Proceedings of the ACM-IEEE international symposium on Empirical software engineering and measurement - ESEM ‘12 (p. 139). ACM Press. DOI: 10.1145/2372251.2372275. 2012. ↩︎
Duvall, Paul M., Matyas, Steve, & Glover, Andrew. Continuous integration: improving software quality and reducing risk. Pearson Education, Inc., 2007. ↩︎ ↩︎ ↩︎ ↩︎
Cauldwell, Patrick. Code Leader: Using people, tools and processes to build successful software. Wiley Publishing, Inc., 2008. ↩︎
Humble, Jez & Farley, David. Continuous Delivery: Reliable Software Releases through Build, Test and Deployment Automation. Addison-Wesley, 2011. ↩︎ ↩︎
Revert a local change in Git
When we have created a commit locally but have not published it to the remote yet, we can use git reset to undo the commit and, if we wish, discard the changes.
Although there are several options for git reset the most used are:
--soft: Does not touch the index file or the working tree at all (but resets the head to, just like all modes do). This leaves all your changed files “Changes to be committed”, as git status would put it. --hard: Resets the index and working tree. Any changes to tracked files in the working tree sinceare discarded. Any untracked files or directories in the way of writing any tracked files are simply deleted. Git reset documentation {: style=“text-align: right;”}
Here there is an example about using git reset. We start by changing a file and creating a commit with the change.
bash-3.2$ cat README.md
# Index
1
bash-3.2$
bash-3.2$ cat README.md
# Index
1
2
bash-3.2$
bash-3.2$ git add README.md
bash-3.2$
bash-3.2$ git commit -m "Add number 2 in README.md"
[main 3734fd5] Add number 2 in README.md
1 file changed, 1 insertion(+)
git status shows there is one commit pending to be published.
bash-3.2$ git status
On branch main
Your branch is ahead of 'origin/main' by 1 commit.
(use "git push" to publish your local commits)
nothing to commit, working tree clean
Using git reflog to see the history.
3734fd5 (HEAD -> main) HEAD@{0}: commit: Add number 2 in README.md
866bfa8 (origin/main) HEAD@{1}: revert: Revert "Merge branch 'feature-1'"
e2f6d08 HEAD@{2}: merge feature-1: Merge made by the 'ort' strategy.
23644da HEAD@{3}: checkout: moving from feature-1 to main
Now we can use git reset --soft <COMMIT_ID> to undo the commit but keep the changes.
bash-3.2$ git reset --soft 866bfa8
bash-3.2$
bash-3.2$ git status
On branch main
Your branch is up to date with 'origin/main'.
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: README.md
git log after using git reset
commit 866bfa8a952d11240707ebfc87f3266034d42443 (HEAD -> main, origin/main)
Author: Julian Nonino <learn.software.eng+jnonino@gmail.com>
Date: Wed Jan 18 20:06:40 2023 -0300
Revert "Merge branch 'feature-1'"
This reverts commit e2f6d08d3b38a02a1c026cfb879f3131536757ac, reversing
changes made to 23644dab9fc5828ecdd358c6d3acb4196ed23546.
We create a new commit so we can test the git reset --hard command.
bash-3.2$ git status
On branch main
Your branch is up to date with 'origin/main'.
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: README.md
bash-3.2$ git commit -m "Add number 2 in README.md - NEW COMMIT"
[main 2e7193d] Add number 2 in README.md - NEW COMMIT
1 file changed, 1 insertion(+)
git log now shows the new commit.
commit 2e7193db650b9ba0762fe73525df599a08f8577d (HEAD -> main)
Author: Julian Nonino <learn.software.eng+jnonino@gmail.com>
Date: Thu Jan 19 08:32:57 2023 -0300
Add number 2 in README.md - NEW COMMIT
commit 866bfa8a952d11240707ebfc87f3266034d42443 (origin/main)
Author: Julian Nonino <learn.software.eng+jnonino@gmail.com>
Date: Wed Jan 18 20:06:40 2023 -0300
Revert "Merge branch 'feature-1'"
This reverts commit e2f6d08d3b38a02a1c026cfb879f3131536757ac, reversing
changes made to 23644dab9fc5828ecdd358c6d3acb4196ed23546.
Now we can use git reset --hard <COMMIT_ID> to undo the commit and discard all the changes.
bash-3.2$ git reset --hard 866bfa8
HEAD is now at 866bfa8 Revert "Merge branch 'feature-1'"
bash-3.2$
bash-3.2$ git status
On branch main
Your branch is up to date with 'origin/main'.
nothing to commit, working tree clean
git log remains as it nothing had happened.
commit 866bfa8a952d11240707ebfc87f3266034d42443 (HEAD -> main, origin/main)
Author: Julian Nonino <learn.software.eng+jnonino@gmail.com>
Date: Wed Jan 18 20:06:40 2023 -0300
Revert "Merge branch 'feature-1'"
This reverts commit e2f6d08d3b38a02a1c026cfb879f3131536757ac, reversing
changes made to 23644dab9fc5828ecdd358c6d3acb4196ed23546.
Revert a pushed change in Git
When we realized that the last commit was a mistake but we already published it, the command to use is git revert <COMMIT_HASH>.
- First we need to locate the ID of the commit we want to revert, it can be done with
git logorgit reflogcommands. - Then, run the
git revert <COMMIT_HASH>command using the ID obtained in the previous step. Use the options-eor--editto edit the commit message if we like. - Push our changes so the revert is available for everyone in our group.
Reverting multiple commits
If we need to revert multiple commits we can revert them one by one using the --no-commit option in order to create a single revert commit at the end.
Imagine the history is like the following and we need to go back to COMMIT-3.
COMMIT-1 -> COMMIT-2 -> COMMIT-3 -> COMMIT-4 -> COMMIT-5 -> COMMIT-6 -> HEAD
This sequence of commands will get our files to the version of COMMIT-3:
bash-3.2$ git revert --no-commit COMMIT-6
bash-3.2$ git revert --no-commit COMMIT-5
bash-3.2$ git revert --no-commit COMMIT-4
bash-3.2$ git commit -m "Revert to version in COMMIT-3"
bash-3.2$ git push
Reverting a merge commit
-m parent-number, –mainline parent-number
Usually you cannot revert a merge because you do not know which side of the merge should be considered the mainline. This option specifies the parent number (starting from 1) of the mainline and allows revert to reverse the change relative to the specified parent.
Git revert documentation {: style=“text-align: right;”}
When we need to revert a merge commit git revert command needs to be run with the -m or --mainline option to indicate the parent number because a merge commit has more than one parent and Git does not know which parent was target branch and which was the branch with the changes that should be reverted.
Here there is an example showing how to revert a merge commit.
Create the first commit in main branch.
bash-3.2$ cat README.md
# Index
1
bash-3.2$
bash-3.2$ git commit -m "Add number 1 in README.md - main branch"
[main (root-commit) 23644da] Add number 1 in README.md - main branch
1 file changed, 3 insertions(+)
create mode 100644 README.md
bash-3.2$
bash-3.2$ git push -u origin main
Enumerating objects: 3, done.
Counting objects: 100% (3/3), done.
Writing objects: 100% (3/3), 254 bytes | 254.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
To github.com:jnonino/test-repo.git
* [new branch] main -> main
branch 'main' set up to track 'origin/main'.
bash-3.2$
The state of the README.md file in main branch.
bash-3.2$git status
On branch main
Your branch is up to date with 'origin/main'.
nothing to commit, working tree clean
bash-3.2$
bash-3.2$ cat README.md
# Index
1
Branch feature-1 created and added one commit.
bash-3.2$ git checkout -b feature-1
Switched to a new branch 'feature-1'
bash-3.2$
bash-3.2$ cat README.md
# Index
1
2
bash-3.2$
bash-3.2$ git add README.md
bash-3.2$
bash-3.2$ git commit -m "Add number 2 in README.md - feature-1 branch"
[feature-1 83ea1a3] Add number 2 in README.md - feature-1 branch
1 file changed, 1 insertion(+)
bash-3.2$
bash-3.2$ git push --set-upstream origin feature-1
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Writing objects: 100% (3/3), 292 bytes | 292.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
remote:
remote: Create a pull request for 'feature-1' on GitHub by visiting:
remote: https://github.com/jnonino/test-repo/pull/new/feature-1
remote:
To github.com:jnonino/test-repo.git
* [new branch] feature-1 -> feature-1
branch 'feature-1' set up to track 'origin/feature-1'.
bash-3.2$
The state of README.md in the feature-1 branch.
bash-3.2$ git status
On branch feature-1
Your branch is up to date with 'origin/feature-1'.
nothing to commit, working tree clean
bash-3.2$
bash-3.2$ cat README.md
# Index
1
2
Merge the feature-1 branch into the main branch.
bash-3.2$ git checkout main
Switched to branch 'main'
Your branch is up to date with 'origin/main'.
bash-3.2$
bash-3.2$ git merge --no-ff feature-1
Merge made by the 'ort' strategy.
README.md | 1 +
1 file changed, 1 insertion(+)
bash-3.2$
bash-3.2$ git push
Enumerating objects: 1, done.
Counting objects: 100% (1/1), done.
Writing objects: 100% (1/1), 233 bytes | 233.00 KiB/s, done.
Total 1 (delta 0), reused 0 (delta 0), pack-reused 0
To github.com:jnonino/test-repo.git
23644da..e2f6d08 main -> main
bash-3.2$
Current state of README.md in main branch.
bash-3.2$ git status
On branch main
Your branch is up to date with 'origin/main'.
nothing to commit, working tree clean
bash-3.2$
bash-3.2$ cat README.md
# Index
1
2
git log after merging feature-1 into main branch.
commit e2f6d08d3b38a02a1c026cfb879f3131536757ac (HEAD -> main, origin/main)
Merge: 23644da 83ea1a3
Author: Julian Nonino <learn.software.eng+jnonino@gmail.com>
Date: Wed Jan 18 19:58:19 2023 -0300
Merge branch 'feature-1'
commit 83ea1a347e0e87b19a611997219089b5b9247d1f (origin/feature-1, feature-1)
Author: Julian Nonino <learn.software.eng+jnonino@gmail.com>
Date: Wed Jan 18 19:53:38 2023 -0300
Add number 2 in README.md - feature-1 branch
commit 23644dab9fc5828ecdd358c6d3acb4196ed23546
Author: Julian Nonino <learn.software.eng+jnonino@gmail.com>
Date: Wed Jan 18 19:48:37 2023 -0300
Add number 1 in README.md - main branch
To revert the merge commit, as it was stated above we need to pay attention to the merge field.
Merge: 23644da 83ea1a3
Running git revert e2f6d08 -m 1 will reinstate the tree as it was in 23644da, and git revert e2f6d08 -m 2 will set the tree as it was in 83ea1a3.
In this example we would like to leave the main branch as it was before the merge commit. For doing that, we need to run git revert e2f6d08 -m 1.
bash-3.2$ git revert e2f6d08 -m 1
[main 866bfa8] Revert "Merge branch 'feature-1'"
1 file changed, 1 deletion(-)
bash-3.2$
bash-3.2$ git status
On branch main
Your branch is ahead of 'origin/main' by 1 commit.
(use "git push" to publish your local commits)
nothing to commit, working tree clean
bash-3.2$
bash-3.2$ git push
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Writing objects: 100% (3/3), 344 bytes | 344.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
To github.com:jnonino/test-repo.git
e2f6d08..866bfa8 main -> main
git log after reverting the merge commit.
commit 866bfa8a952d11240707ebfc87f3266034d42443 (HEAD -> main, origin/main)
Author: Julian Nonino <learn.software.eng+jnonino@gmail.com>
Date: Wed Jan 18 20:06:40 2023 -0300
Revert "Merge branch 'feature-1'"
This reverts commit e2f6d08d3b38a02a1c026cfb879f3131536757ac, reversing
changes made to 23644dab9fc5828ecdd358c6d3acb4196ed23546.
commit e2f6d08d3b38a02a1c026cfb879f3131536757ac
Merge: 23644da 83ea1a3
Author: Julian Nonino <learn.software.eng+jnonino@gmail.com>
Date: Wed Jan 18 19:58:19 2023 -0300
Merge branch 'feature-1'
commit 83ea1a347e0e87b19a611997219089b5b9247d1f (origin/feature-1, feature-1)
Author: Julian Nonino <learn.software.eng+jnonino@gmail.com>
Date: Wed Jan 18 19:53:38 2023 -0300
Add number 2 in README.md - feature-1 branch
commit 23644dab9fc5828ecdd358c6d3acb4196ed23546
Author: Julian Nonino <learn.software.eng+jnonino@gmail.com>
Date: Wed Jan 18 19:48:37 2023 -0300
Add number 1 in README.md - main branch
Current state of README.md in main branch.
bash-3.2$ git status
On branch main
Your branch is up to date with 'origin/main'.
nothing to commit, working tree clean
bash-3.2$
bash-3.2$ cat README.md
# Index
1