Al desplegar una aplicación en Kubernetes utilizando un objeto del tipo Deployment, los pods pertenecientes a dicho Deployment pueden ser creados y destruidos en cualquier momento en base a su funcionamiento, por ejemplo si en nuestro Deployment pedimos que existan 3 réplicas y por cualquier razón alguna de ellas deja de funcionar, una nueva réplica será creada automáticamente para reemplazar a la que falló.
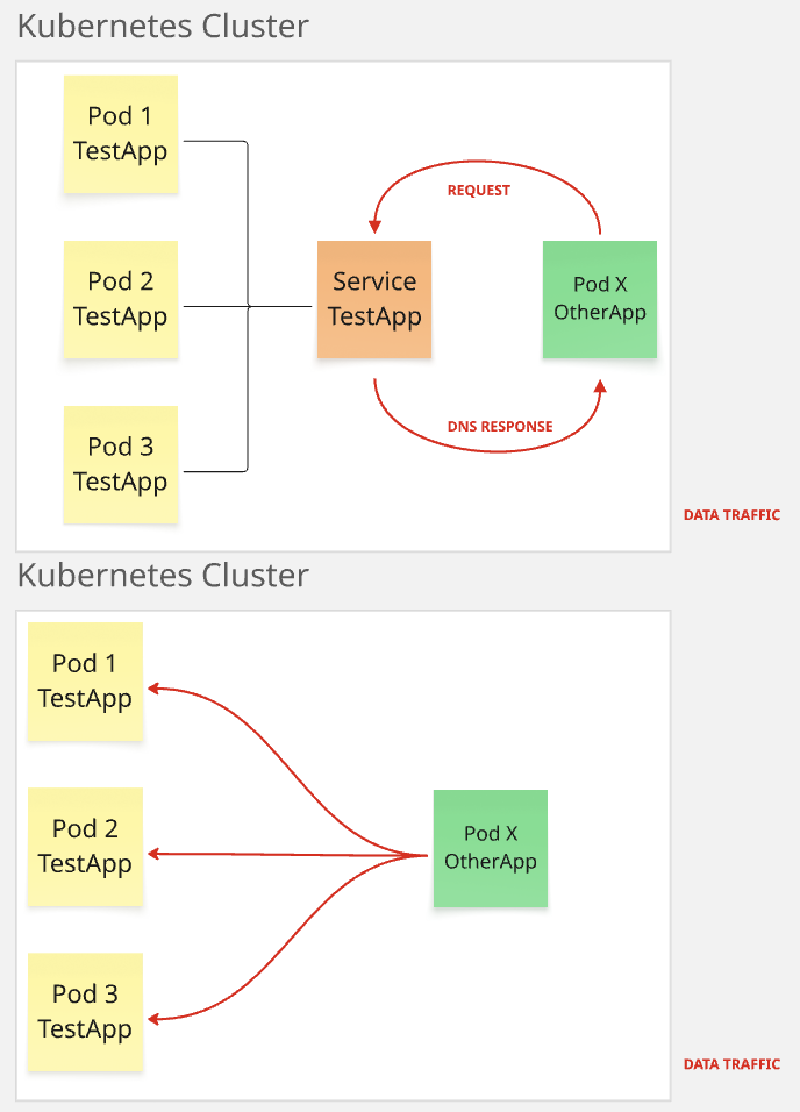
Cada pod tiene su propia dirección IP dentro del cluster. En general, las demás aplicaciones que necesitan interactuar con nuestra aplicación desconocen el nombre de cada una de sus replicas, su estado y su dirección IP para iniciar una comunicación. Kubernetes nos provee el objeto Service como una forma nativa de Service Discovery sin que necesitemos hacer cambios en nuestra aplicación o en las que necesitan comunicarse con ella. Entonces, el fin para el cual creamos un servicio es para exponer una aplicación que puede estar constituida por múltiples pods a traves de un único punto de acceso. De esta manera otras aplicación contactaran al Service y este redirigirá la comunicación a alguno de los pods de nuestra aplicación.
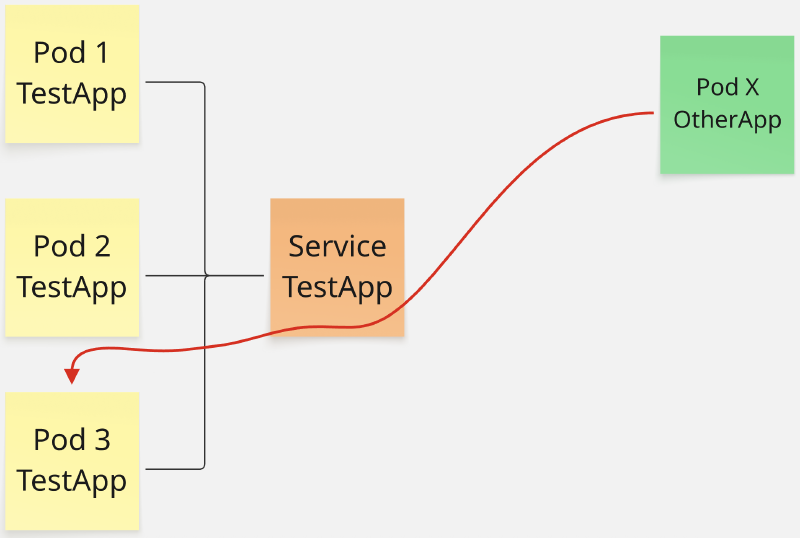
Creando un servicio#
Un Service puede crearse mediante una declaración en un archivo .yaml al igual que otros objetos de Kubernetes. Por ejemplo:
apiVersion: v1
kind: Service
metadata:
name: servicio-de-prueba
spec:
type: ClusterIP
selector:
app_name: mi-aplicacion
ports:
- protocol: TCP
port: 8080
targetPort: 1234En dicho ejemplo, estaremos creando un servicio llamado my-service del tipo ClusterIP que redirige las comunicaciones que llegan al puerto 8080 hacia el puerto 1234 de cualquier Pod que tenga la etiqueta app-name: my-app.
Como se ve en el archivo, el campo ports es del tipo array, lo que significa que pueden mapearse múltiples puertos.
Cada definición de un puerto debe contener los siguientes campos:
- port: es el puerto en el que el servicio estará accesible dentro del cluster. No puede omitirse.
- targetPort: es un valor opcional, indica el puerto en el cual el pod estará recibiendo las comunicaciones. Si se omite, se asume que es el mismo valor que el indicado en el campo port. Puede ser un número o el nombre del puerto si es que en el pod se especificaron nombres. Se recomienda utilizarlo sólo cuando difiere del valor de port.
- protocol: establece el protocolo utilizado para las comunicaciones, los valores válidos son: SCTP, TCP y UDP. En caso de no indicarse explícitamente, el valor por defecto es TCP.
- name: permite darle un nombre al puerto. Es útil para referenciar por DNS o en situaciones donde hay múltiples puertos en un mismo servicio. Es un valor opcional, pero dentro de un mismo servicio, cada puerto debe tener un nombre único.
Tipos de servicios#
Como se muestra en la sección anterior, el tipo de servicio se especifica mediante el valor spec.type:
apiVersion: v1
kind: Service
metadata:
name: servicio-de-prueba
spec:
...
type: <TIPO_DE_SERVICIO>
...A continuación veremos cada uno de ellos.
ClusterIP#
Es el tipo de servicio por defecto. Kubernetes asigna una dirección IP al servicio que las demás aplicaciones pueden utilizar para comunicarse. La dirección asignada proviene de un grupo de direcciones reservadas para este fin mediante el valor service-cluster-ip-range en el servidor de API de Kubernetes.
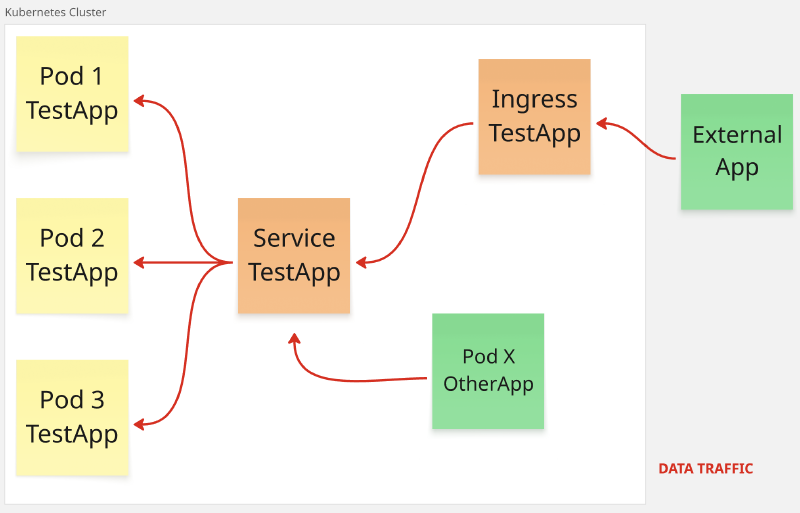
Cuando se crea un servicio del tipo ClusterIP el servicio no es accesible desde el exterior y los pods detrás de este servicio solo pueden ser contactados por otros pods del mismo cluster. Si se desea exponer el servicio al exterior se debe utilizar un objeto del tipo Ingress.
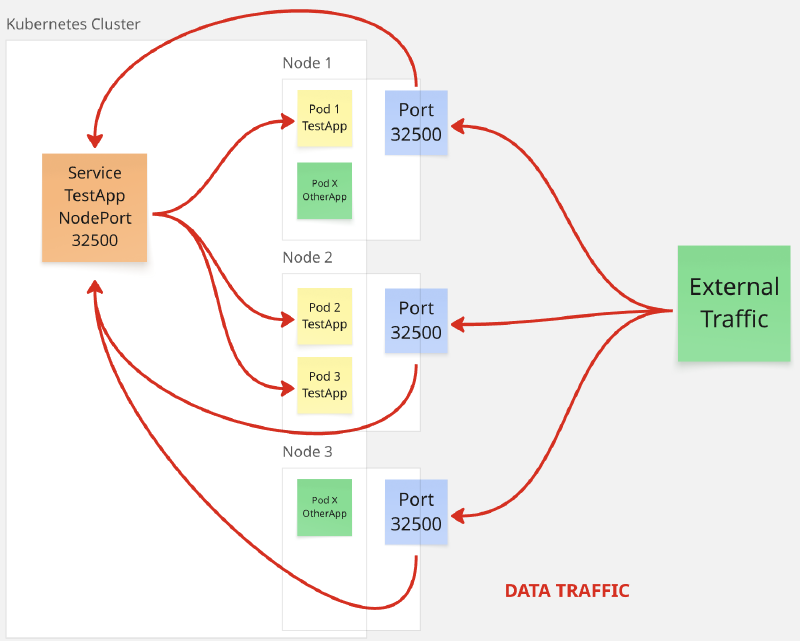
NodePort#
En este caso, Kubernetes asigna al servicio un puerto del rango definido en la configuración service-node-port-range, usualmente entre los puertos 30000 y 32767. Luego, cada nodo abre dicho puerto para las comunicaciones hacia el servicio.
Este tipo de servicio, permite un rápido acceso desde el exterior sin necesidad de infraestructura adicional, pero no contempla un mecanismo de balance de carga (load balancing), lo que puede provocar la saturación de alguno de ellos. Por otro lado, en un sistema donde existan múltiples servicios, la gestión de puertos puede volverse demasiado compleja.
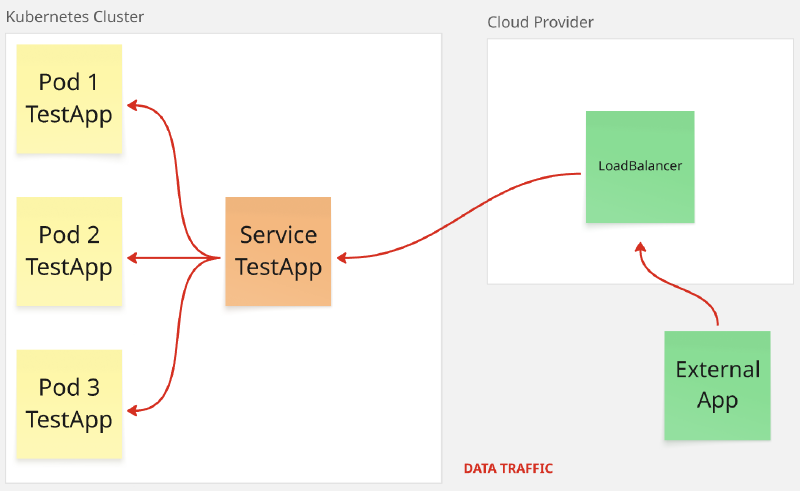
LoadBalancer#
En proveedores de servicios en la nube que soporten load balancers como Amazon Web Services, Google Cloud Platform o Microsoft Azure, crear un servicio de este tipo dispara la creación de un load balancer externo en la platform de nube utilizada. La creación ocurre de manera asíncrona e información sobre su estado es publicada en el estado del servicio (.status.loadbalancer).
El proveedor de servicios en la nube decide como se balancea la carga.
La gran ventaja de este tipo de servicio es que mediante el uso de servicios en la nube se obtiene un balanceo de carga automático y de alta disponibilidad. La desventaja es que puede generar costos adicionales.
ExternalName#
Este tipo de servicio redirecciona el tráfico a un nombre de DNS en lugar de a un conjunto de pods. El DNS al cual se apunta, se indica mediante el campo .spec.externalName
Por ejemplo, redirige las comunicaciones hacia la dirección learn-software.com.
apiVersion: v1
kind: Service
metadata:
name: mi-servicio
spec:
type: ExternalName
externalName: learn-software.com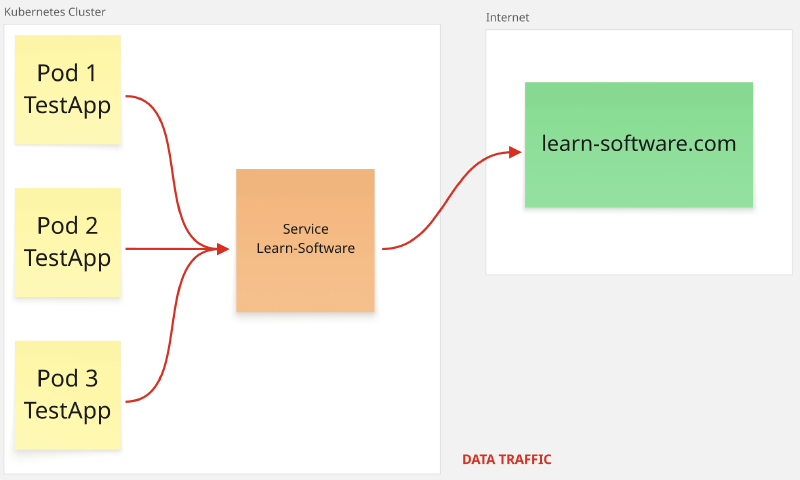
Headless Services#
Existen casos en los que, por ejemplo, es necesario utilizar otros mecanismos de Service Discovery o en los que necesitemos conocer las direcciones IP de todos aquellos pods que podríamos contactar. Para ello existen los headless services. Se crean indicando el valor None en el campo .spec.clusterIP.
Un headless service no tiene asignada una dirección IP única del cluster. Retorna directamente las direcciones IPs de pods en una respuesta DNS. Esto es útil para descubrimiento de servicios personalizados, bases de datos distribuidas o control detallado del balanceo. La desventaja es que el cliente del servicio debe ser capaz de resolver y gestionar por sí mismo una respuesta DNS conteniendo múltiples direcciones.