Vectores, Escalares y Espacios Vectoriales
En 2017, investigadores de Google Brain publicaron Attention Is All You Need, el artículo que introdujo la arquitectura Transformer sobre la que hoy se construyen GPT-4, Gemini y prácticamente todos los modelos de lenguaje de vanguardia. En el corazón de esa arquitectura (y de toda red neuronal, sistema de recomendación y modelo de visión por computadora—) vive un objeto engañosamente simple: el vector.
Cuando un modelo de lenguaje lee la palabra “banco”, no ve una cadena de texto. Ve un vector en un espacio de 4096 dimensiones donde “banco (financiero)” y “banco (asiento)” ocupan regiones mensurablemente distintas. Cuando un motor de búsqueda decide que tu consulta coincide con un documento, está calculando el ángulo entre dos vectores. Cuando una red neuronal aprende, está desplazando vectores por el espacio en respuesta a un gradiente, que es, él mismo, otro vector.
Este artículo construye tu fundamento operativo para todo eso. Al terminar de leerlo, podrás:
- Definir formalmente vectores, escalares y espacios vectoriales, y explicar por qué importan los axiomas.
- Calcular normas, productos punto y ángulos entre vectores a mano y con NumPy.
- Razonar geométricamente sobre datos de alta dimensión, una habilidad indispensable en investigación en Machine Learning.
- Leer un artículo de investigación con notación vectorial sin perder el hilo.
Sin mas preámbulos, empecemos.
Prerrequisitos
Antes de leer este artículo, deberías manejar con comodidad:
- Álgebra de secundaria: variables, funciones, el plano cartesiano.
- Python básico: listas, bucles, funciones, importación de bibliotecas.
- Intuición de cálculo (útil, no obligatorio): la idea de que una derivada apunta en la dirección de mayor pendiente.
Intuición primero
La analogía del programador: vectores como arreglos tipados con alma geométrica
Como desarrollador, has usado arreglos toda tu carrera. Una lista de Python [3.0, -1.5, 7.2] almacena tres números. Un vector es superficialmente lo mismo, pero con una estructura adicional crucial: posición en el espacio y la geometría que conecta posiciones.
Considera este ejemplo. Supón que tienes dos diccionarios que representan usuarios de una plataforma de comercio electrónico:
usuario_A = {"edad": 28, "freq_compras": 5, "gasto_promedio": 1200.0}
usuario_B = {"edad": 29, "freq_compras": 6, "gasto_promedio": 1150.0}Como diccionarios, son solo contenedores de datos. Puedes leer valores, pero "¿qué tan similares son estos usuarios?" no es una pregunta que el diccionario pueda responder de forma nativa. Ahora conviértelos en vectores:
A = [28, 5, 1200.0]
B = [29, 6, 1150.0]De repente tienes geometría. Puedes medir la distancia entre ellos, el ángulo que forman respecto al origen, y si uno es una versión escalada del otro. Este es el salto que dan los vectores sobre los arreglos simples: viven en un espacio equipado con reglas para medir, comparar y transformar.
El diagrama conceptual: vectores como flechas
Imagina un sistema de coordenadas 2D estándar. El vector es una flecha que parte del origen y termina en el punto . Dos cosas lo definen completamente: su magnitud (qué tan larga es la flecha) y su dirección (hacia dónde apunta).
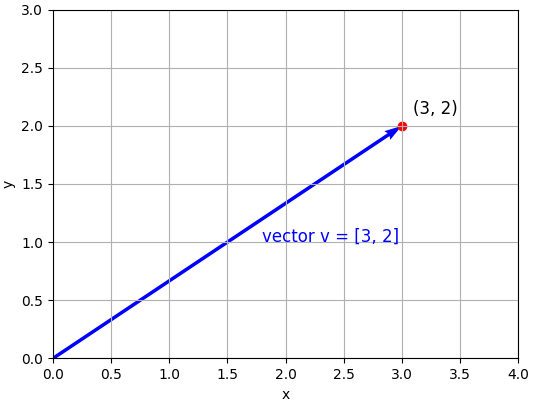
Representación visual de un vector en dos dimensiones
Esta interpretación geométrica no es solo azúcar visual. En aprendizaje automático, un punto de datos (una fila en tu dataset) es un vector, es una flecha en el espacio de características. Dos puntos similares son flechas apuntando en direcciones parecidas. Un valor atípico es una flecha apuntando hacia algún lugar inesperado. La reducción de dimensionalidad (PCA, UMAP) es el arte de encontrar un espacio de menor dimensión donde esas flechas cuenten esencialmente la misma historia.
Escalares: el caso más simple
Un escalar es simplemente un número solo, sin dirección, sin componentes. La temperatura, el valor de pérdida (loss), la tasa de aprendizaje: todos son escalares. Cuando multiplicas un vector por un escalar, estiras o encoges la flecha sin rotarla:
Misma dirección, el doble de largo.
2 x [3, 2] = [6, 4]Misma dirección, invertida (180°).
-1 x [3, 2] = [-3, -2]Esta operación, multiplicación escalar, es una de las dos operaciones fundamentales que definen un espacio vectorial.
Derivación matemática
Definiciones formales
Escalar
Un elemento de un campo , para nuestros propósitos, un número real o complejo . Se denota con itálicas estándar y generalmente letras griegas: , , .
Vector
Una tupla ordenada de escalares de . Un vector real de dimensiones es un elemento del espacio :
Espacio vectorial
Un conjunto de vectores sobre un campo , equipado con dos operaciones para las cuales será cerrado.
Suma de vectores: para todo . Operación interna con las propiedades:
- Propiedad Asociativa: .
- Propiedad Conmutativa: .
- Existencia del elemento neutro: existe un elemento , denominado vector nulo, tal que para todo .
- Existencia del inverso aditivo: para todo , existe un elemento tal que .
Multiplicación por escalar: para todo . Operación externa con las propiedades:
- Propiedad Asociativa: .
- Existencia del elemento neutro: existe un escalar , tal que para todo .
- Propiedad distributiva respecto de la suma vectorial: Para cualquier escalar , se cumple que para todo .
- Propiedad distributiva respecto de la suma de escalares: Para cualquier par de escalares y , se cumple que para todo .
¿Qué significa que el espacio vectorial es cerrado para esas dos operaciones?
Significa que producen resultados que pertenecen al mismo espacio vectorial.
- Si y entonces .
- Para cualquier escalar y vector , entonces .
Suma de vectores
Dados y :
Normas de vectores
La norma de un vector mide su longitud. La más común es la norma euclidiana (norma ):
La familia general es la norma :
Dos casos especiales aparecen constantemente en Machine Learning (ML):
Norma (Manhattan):
Usada en regularización LASSO porque induce dispersión (sparsity), penaliza cualquier componente no nulo por igual.
Norma (norma máximo):
Útil cuando te importa la activación más grande de un vector, ignorando las demás.
Para investigar más sobre normas de vectores, entrá a este artículo de Wikipedia.
El producto punto
El producto punto (o producto interno) de dos vectores es:
El producto punto de un vector consigo mismo es igual a su magnitud al cuadrado.
El ángulo entre vectores
Aquí es donde la geometría y el álgebra se fusionan elegantemente. De la geometría euclidiana, la Ley de Cosenos establece que para un triángulo con lados , , y ángulo opuesto al lado :
Apliquemos esto a vectores. Sean y dos vectores. El tercer lado del triángulo que forman es .
Sustituyendo , , :
Expandiendo el lado izquierdo mediante el producto punto:
Cancelando y de ambos lados:
Dividiendo ambos lados entre (asumiendo que ninguno es el vector cero):
Interpretaciones clave:
- (): los vectores apuntan en la misma dirección (temas idénticos en un embedding de documentos).
- () los vectores son ortogonales, completamente no relacionados
- (): los vectores apuntan en direcciones opuestas (antónimos en un espacio de embeddings bien entrenado).
En el paper original de Word2Vec (Mikolov et al., 2013), la famosa analogía:
funciona precisamente gracias a esta geometría. Las relaciones semánticas se codifican como direcciones en el espacio vectorial, y encontrar reina significa hallar el vector con mayor similitud coseno al vector de consulta. Todo modelo de embedding moderno (BERT, GPT, sentence-transformers) hereda esta filosofía geométrica. La siguiente vez que leas sobre “espacios de representación” en un paper de IA, recuerda: están hablando literalmente de la geometría que acabas de derivar.
El producto vectorial (producto cruz)
El producto punto toma dos vectores y devuelve un escalar. El producto vectorial toma dos vectores en y devuelve un vector, uno que es perpendicular a ambas entradas. Está definido únicamente en tres (y siete) dimensiones, lo que lo hace más especializado geométricamente que el producto punto.
Dados y , el producto vectorial se calcula expandiendo el siguiente determinante simbólico:
Expandiendo por la primera fila:
Dos propiedades geométricas definen el producto vectorial por completo:
- Dirección: es siempre ortogonal tanto a como a . Podés verificarlo directamente: y . La orientación sigue la regla de la mano derecha: curvá los dedos de tu mano derecha desde hacia , y el pulgar apunta en la dirección de .
Magnitud: La longitud del resultado es igual al área del paralelogramo generado por y :
Propiedad algebraica clave, anticonmutatividad:
Intercambiar el orden invierte el signo y la dirección. Esto significa que el producto vectorial no es conmutativo, a diferencia del producto punto.
Implementación en Python
Implementamos todo desde cero: primero en Python puro para ver la mecánica, luego verificamos con NumPy.
Código
"""
Curso: Inteligencia Artificial
Módulo: Algebra Lineal
Artículo: Vectores, Escalares y Espacios Vectoriales
Implementación en NumPy
Python 3.10+
"""
import math
from typing import List
#########################
# Operaciones vectoriales
#########################
def suma_vectores(u: List[float], v: List[float]) -> List[float]:
"""
Suma dos vectores componente a componente.
Requiere: u y v tienen la misma dimensión.
"""
assert len(u) == len(v), f"Error de dimensión: {len(u)} vs {len(v)}"
return [u_i + v_i for u_i, v_i in zip(u, v)]
def multiplicacion_escalar(alpha: float, v: List[float]) -> List[float]:
"""
Multiplica un vector por un escalar.
Estira/encoge la flecha; un alpha negativo la invierte 180°.
"""
return [alpha * v_i for v_i in v]
def norma_l2(v: List[float]) -> float:
"""
Norma euclidiana (L2): la longitud geométrica del vector v.
Es el teorema de Pitágoras generalizado a n dimensiones.
"""
return math.sqrt(sum(v_i ** 2 for v_i in v))
def norma_l1(v: List[float]) -> float:
"""
Norma Manhattan (L1): suma de valores absolutos.
Induce dispersión (sparsity), usada en regularización LASSO.
"""
return sum(abs(v_i) for v_i in v)
def producto_punto(u: List[float], v: List[float]) -> float:
"""
Producto punto: suma de productos componente a componente.
Devuelve un escalar que mide cuánto se 'alinean' u y v.
Requiere: u y v tienen la misma dimensión.
"""
assert len(u) == len(v), f"Error de dimensión: {len(u)} vs {len(v)}"
return sum(u_i * v_i for u_i, v_i in zip(u, v))
def similitud_coseno(u: List[float], v: List[float]) -> float:
"""
Similitud coseno: producto_punto(u,v) / (||u|| * ||v||).
Devuelve un valor en [-1, 1].
1.0 -> misma dirección (similitud máxima)
0.0 -> ortogonales (sin relación)
-1.0 -> direcciones opuestas (totalmente disímiles)
"""
norma_u = norma_l2(u)
norma_v = norma_l2(v)
# Protección contra división por cero (el vector cero no tiene dirección)
if norma_u == 0 or norma_v == 0:
raise ValueError("La similitud coseno no está definida para el vector cero.")
return producto_punto(u, v) / (norma_u * norma_v)
def angulo_entre(u: List[float], v: List[float], grados: bool = True) -> float:
"""
Ángulo entre dos vectores en radianes o grados.
Usa: theta = arccos(similitud_coseno(u, v))
IMPORTANTE: aplicamos 'clamp' antes de arccos para evitar errores
de punto flotante que empujan cos ligeramente fuera de [-1, 1].
"""
cos_theta = similitud_coseno(u, v)
cos_theta = max(-1.0, min(1.0, cos_theta)) # clamp numérico
theta_rad = math.acos(cos_theta)
return math.degrees(theta_rad) if grados else theta_rad
def normalizar(v: List[float]) -> List[float]:
"""
Devuelve el vector unitario (longitud 1) que apunta en la
misma dirección que v.
Fórmula: v_hat = v / ||v||
Los vectores unitarios son útiles cuando importa la DIRECCIÓN,
no la magnitud. En similitud coseno solo importa la dirección,
así que trabajar con vectores normalizados es equivalente
y computacionalmente más eficiente.
"""
norma = norma_l2(v)
if norma == 0:
raise ValueError("No se puede normalizar el vector cero.")
return [v_i / norma for v_i in v]
#########
# Ejemplo
#########
if __name__ == "__main__":
# Dos vectores en 3 dimensiones
# Imagínalos como embeddings de dos documentos
u = [1.0, 2.0, 3.0]
v = [4.0, 0.0, -1.0]
print("=======================================")
print("Operaciones vectoriales con Python puro")
print("=======================================")
print(f"u = {u}")
print(f"v = {v}")
print(f"Suma (u + v) -> {suma_vectores(u, v)}")
print(f"Multiplicación escalar (2 * u) -> {multiplicacion_escalar(2.0, u)}")
print(f"Norma L2 de u (||u||₂) -> {norma_l2(u):.4f}")
print(f"Norma L1 de u (||u||₁) -> {norma_l1(u):.4f}")
print(f"Producto punto (u · v) -> {producto_punto(u, v):.4f}")
print(f"Similitud coseno -> {similitud_coseno(u, v):.4f}")
print(f"Ángulo entre u y v -> {angulo_entre(u, v):.2f}°")
print(f"Vector unitario de u (û) -> {[round(x, 4) for x in normalizar(u)]}")
u_hat = normalizar(u)
print(f"Verificar `||û||₂ = 1` -> {norma_l2(u_hat):.6f}")
print("==========================")
print("Demo de analogía semántica")
print("==========================")
print("En NLP real, estos serían embeddings aprendidos por un modelo.")
print("Aquí ilustramos el principio con vectores de características")
print("creados manualmente.")
print("Características: [realeza, masculinidad, edad_relativa, poder]")
rey = [0.9, 0.9, 0.8, 0.9]
reina = [0.9, 0.1, 0.8, 0.9]
hombre = [0.0, 0.9, 0.5, 0.4]
mujer = [0.0, 0.1, 0.5, 0.4]
print(f"rey = {rey}")
print(f"reina = {reina}")
print(f"hombre = {hombre}")
print(f"mujer = {mujer}")
print("La famosa analogía: rey - hombre + mujer ≈ reina")
vector_analogia = suma_vectores(
suma_vectores(rey, multiplicacion_escalar(-1.0, hombre)),
mujer
)
sim_reina = similitud_coseno(vector_analogia, reina)
sim_rey = similitud_coseno(vector_analogia, rey)
print(f"rey - hombre + mujer -> {[round(x, 2) for x in vector_analogia]}")
print(f"Similitud coseno con 'reina': {sim_reina:.4f}")
print(f"Similitud coseno con 'rey': {sim_rey:.4f}")
print("==> El vector de analogía está más cerca de 'reina' que de 'rey'.")
Salida
> python vector_pure_python.es.py
=======================================
Operaciones vectoriales con Python puro
=======================================
u = [1.0, 2.0, 3.0]
v = [4.0, 0.0, -1.0]
Suma (u + v) -> [5.0, 2.0, 2.0]
Multiplicación escalar (2 * u) -> [2.0, 4.0, 6.0]
Norma L2 de u (||u||₂) -> 3.7417
Norma L1 de u (||u||₁) -> 6.0000
Producto punto (u · v) -> 1.0000
Similitud coseno -> 0.0648
Ángulo entre u y v -> 86.28°
Vector unitario de u (û) -> [0.2673, 0.5345, 0.8018]
Verificar `||û||₂ = 1` -> 1.000000
==========================
Demo de analogía semántica
==========================
En NLP real, estos serían embeddings aprendidos por un modelo.
Aquí ilustramos el principio con vectores de características
creados manualmente.
Características: [realeza, masculinidad, edad_relativa, poder]
rey = [0.9, 0.9, 0.8, 0.9]
reina = [0.9, 0.1, 0.8, 0.9]
hombre = [0.0, 0.9, 0.5, 0.4]
mujer = [0.0, 0.1, 0.5, 0.4]
La famosa analogía: rey - hombre + mujer ≈ reina
rey - hombre + mujer -> [0.9, 0.1, 0.8, 0.9]
Similitud coseno con 'reina': 1.0000
Similitud coseno con 'rey': 0.8902
==> El vector de analogía está más cerca de 'reina' que de 'rey'.Perspectiva de Machine Learning e IA
Los vectores no son un concepto preliminar del que te graduarás, son la lingua franca de la investigación moderna en IA. Aquí tres formas en que aparecen en en contexto de Inteligencia Artificial y Machine Learning.
Espacios de embedding y aprendizaje de representaciones. Todo modelo de aprendizaje profundo moderno aprende a representar entradas como vectores. Los embeddings de tokens del Transformer que se describen en el artículo Attention Is All You Need, son vectores en (típicamente entre 512 y 4096 dimensiones). El proceso de entrenamiento completo puede verse como una optimización de la geometría de esos vectores para que entradas semánticamente similares queden agrupadas. La investigación en aprendizaje contrastivo enmarca explícitamente el objetivo del aprendizaje como: acercar vectores de muestras similares y alejar vectores de muestras distintas en el espacio de embedding.
Generación Aumentada con Recuperación (RAG) y bases de datos vectoriales. Con la explosión de los LLMs, una dirección clave de investigación aplicada es la búsqueda eficiente del vecino más cercano sobre miles de millones de vectores. En el artículo Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, Lewis et al. demostraron que aumentar la generación con documentos recuperados mejora dramáticamente la precisión factual. El paso de recuperación completo es una búsqueda por similitud coseno, exactamente la fórmula que vimos antes.
Dimensionalidad. La geometría de los espacios de alta dimensión es profundamente contraria a la intuición, un fenómeno conocido como la maldición de la dimensionalidad. En dimensiones muy altas, casi todos los pares de vectores se vuelven casi ortogonales (), lo que puede degradar la similitud coseno como métrica significativa. Entender cuándo falla la similitud coseno y qué alternativas geométricas existen (espacios hiperbólicos, variedades de Riemann) es un área de investigación activa. Si esto te interesa, Poincaré Embeddings es un excelente punto de entrada.
Errores comunes y depuración
Olvidar normalizar antes de computar similitud coseno, y cuándo NO hacerlo. La similitud coseno mide dirección solamente, descartando la magnitud. Si dos documentos son similares pero uno es diez veces más largo, la similitud coseno ignora esa diferencia. A veces eso es un error (cuando la magnitud importa), a veces es una ventaja (clasificación de sentimiento donde importa el tema, no la extensión). Siempre pregunta: ¿debería importar la magnitud aquí? Si la respuesta es sí, usa distancia euclidiana en su lugar.
Errores de dimensión que producen resultados silenciosamente incorrectos. En NumPy,
np.dot(u, v)lanzará un error si las dimensiones no coinciden para arreglos 1D, pero con arreglos 2D (matrices), NumPy puede hacer broadcasting de formas que devuelven un resultado con la forma equivocada. Siempre verificaassert u.shape == v.shapeantes de productos punto en código de investigación, o usanp.einsumcon notación de índices explícita para mayor claridad.El caso límite del vector cero.
similitud_coseno([0,0,0], [1,2,3])es matemáticamente indefinido (estás dividiendo entre cero). En sistemas de producción que calculan embeddings, un vector cero normalmente señala un error en etapas anteriores: entrada vacía, tokenización incorrecta, o una capa de red que colapsó. Si ves pérdidasNaN, verifica las normas de tus embeddings primero.Errores de precisión de punto flotante en
arccos. Debido a la aritmética de punto flotante, los productos punto pueden ocasionalmente producir valores de coseno ligeramente fuera de (por ejemplo,1.0000000002). Pasar este valor directamente amath.acos()lanza unValueError. Aplica siempre clamp:cos_theta = max(-1.0, min(1.0, cos_theta))antes de llamar aarccos.Confundir los efectos de regularización y . La regularización (weight decay) encoge todos los pesos proporcionalmente, nunca los lleva exactamente a cero. La regularización sí lleva pesos a cero, creando modelos dispersos. Esto es consecuencia directa de la geometría de las bolas de norma vs . Elegir el regularizador equivocado es fuente común de modelos demasiado densos (cómputo desperdiciado) o no suficientemente dispersos (baja interpretabilidad).
Resumen y lo que sigue
Puntos clave de este artículo:
- Un vector es una tupla ordenada de escalares que vive en un espacio geométrico, tiene magnitud y dirección.
- Un espacio vectorial se define por cerradura bajo adición y multiplicación escalar, por eso las operaciones lineales en redes neuronales se comportan tan bien.
- La norma mide longitud euclidiana. La norma mide distancia Manhattan y promueve dispersión.
- El producto punto () mide alineación. Dividir entre ambas normas da la similitud coseno, la métrica angular central en recuperación, embeddings y mecanismos de atención.
- La fórmula se deriva de la Ley de Cosenos, no es arbitraria, es geometría.
- Los vectores de alta dimensión son el lenguaje en el que está escrito todo el Machine Learning moderno. La fluidez aquí se multiplica en cada tema futuro.
En el próximo artículo (Matrices y Transformaciones Lineales): Generalizamos de vectores individuales a colecciones de vectores, introducimos las matrices como funciones que transforman espacios vectoriales, y derivamos las reglas de multiplicación de matrices desde primeros principios. Verás exactamente por qué una capa totalmente conectada en una red neuronal no es más que una multiplicación de matrices seguida de una no linealidad.
¡Gracias por llegar hasta acá! Espero que este recorrido por el universo de la IA haya sido tan apasionante para vos como lo fue para mí escribirlo.
Nos encantaría escuchar lo que pensás, así que no te quedes callado/a, dejá tus comentarios, sugerencias y todas esas ideas copadas que seguro se te ocurrieron.
Vas a encontrar todo el código y los proyectos en nuestro repositorio de GitHub learn-software-engineering/examples.
¡Gracias por ser parte de esta comunidad de aprendizaje. Seguí programando y explorando nuevos territorios en este fascinante mundo de la computación!